In today’s data-driven world, organizations generate terabytes and petabytes of information every day. Processing such huge datasets on a single machine becomes slow, expensive, and unreliable. This is where the MapReduce programming model becomes important.
Big companies process huge amounts of data every second.
Think about:
- Millions of customer records
- Website logs
- Online transactions
- Videos and images
- Search engine data
A single computer cannot handle this efficiently.
So engineers use a special method called MapReduce.
In this blog, we will understand MapReduce in a very simple and beginner-friendly way using Google concepts and examples in Golang.
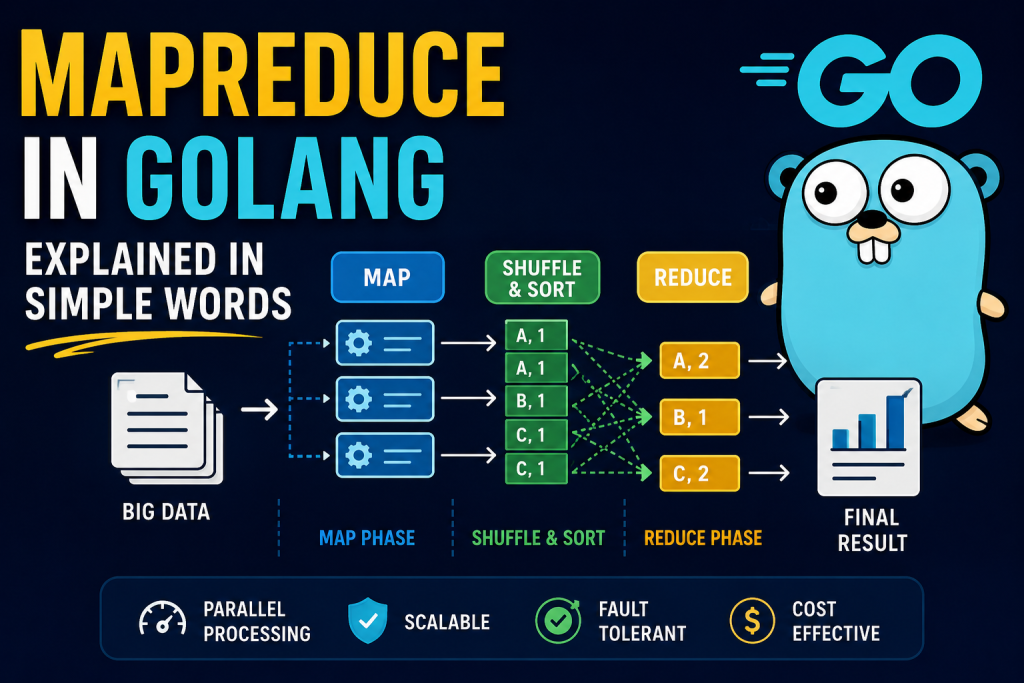
What is MapReduce?
MapReduce is a programming model used to process very large data by dividing work into smaller tasks and running them in parallel.
Simple meaning:
Big Work
↓
Split into Small Work
↓
Many Workers Process Together
↓
Combine Final ResultIt helps systems become:
- Faster
- Scalable
- Efficient
- Fault tolerant
Real-Life Example
Imagine your teacher gives your class a task:
Count how many times each fruit name appears in 500 books.
If one student does everything:
- It will take many days.
Instead, the teacher divides the work.
Student 1
Reads 50 books.
Student 2
Reads another 50 books.
Student 3
Reads another 50 books.
Each student counts fruits separately.
Then the teacher combines all counts.
This is exactly how MapReduce works.
Two Main Parts of MapReduce
MapReduce has two major phases:
- Map Phase
- Reduce Phase
1. MAP Phase
The Map step breaks data into small pieces and processes them independently.
Suppose input data is:
apple mango apple bananaThe mapper converts it into:
apple = 1
mango = 1
apple = 1
banana = 1The mapper simply says:
- “I found one apple”
- “I found one mango”
It creates small key-value pairs.
2. REDUCE Phase
The Reduce step combines similar data.
Input:
apple = 1
apple = 1
banana = 1Reducer combines them:
apple = 2
banana = 1Now we know the final count.
Complete Flow of MapReduce
Large Data
↓
Split Data
↓
Map Workers
↓
Shuffle & Group
↓
Reduce Workers
↓
Final OutputWhy MapReduce is Important
Without MapReduce:
- One machine becomes overloaded
- Processing becomes slow
- Large files become difficult to manage
With MapReduce:
- Many systems work together
- Processing becomes faster
- Data handling becomes scalable
Example from Real Companies
Companies like:
- Amazon
- Netflix
- Meta
use MapReduce ideas for:
- Search engines
- Video recommendations
- Log analysis
- Customer analytics
- Report generation
Understanding MapReduce with a Tea Shop Example
Suppose you own a tea shop chain.
You want to calculate:
Total tea sold across 100 branches.
Without MapReduce:
- One person checks all branch records.
Very slow.
With MapReduce:
MAP
Each branch calculates its own tea sales.
Example:
Branch A = 500 cups
Branch B = 700 cups
Branch C = 300 cupsREDUCE
Combine everything:
Total Tea Sold = 1500 cupsSimple and fast.
Why Golang is Great for MapReduce
Go is excellent for concurrent programming.
Go provides:
Goroutines
Lightweight threads for parallel work.
Channels
Communication between workers.
Fast Performance
Compiled and optimized.
Simple Syntax
Easy to learn.
Simple Golang Example
Let us count words using Go.
go java go python
package main
import (
"fmt"
"strings"
)
func main() {
text := "go java go python"
words := strings.Split(text, " ")
wordCount := make(map[string]int)
// MAP PROCESS
for _, word := range words {
wordCount[word]++
}
// REDUCE OUTPUT
for key, value := range wordCount {
fmt.Println(key, value)
}
}Output
go 2
java 1
python 1Understanding the Code
Step 1 — Split Words
words := strings.Split(text, " ")Converts sentence into word list.
Step 2 — Map Process
wordCount[word]++Counts each word occurrence.
Step 3 — Reduce Output
fmt.Println(key, value)Shows final combined result.
Real MapReduce Systems
Large-scale systems use distributed frameworks like:
Apache Hadoop
Popular for batch processing large datasets.
Components
- HDFS (Storage)
- MapReduce Engine
- YARN (Resource Management)
Apache Spark
A faster modern alternative using in-memory processing.
Where MapReduce is Used
Log Processing
Analyze server logs.
Search Engines
Index billions of pages.
Analytics
Generate reports from large datasets.
Recommendation Systems
Movie or product suggestions.
Fraud Detection
Analyze suspicious transactions.
Advantages of MapReduce
Fast Processing
Parallel workers increase speed.
Scalability
Add more servers when data grows.
Fault Tolerance
If one machine fails, another continues.
Cost Effective
Uses commodity hardware.
Limitations of MapReduce
MapReduce is powerful but not perfect.
Not Real-Time
Mostly used for batch jobs.
Disk Heavy
Frequent reading and writing to disk.
Complex for Small Tasks
Not useful for tiny datasets.
Simple Visualization
Imagine this:
1 Huge Task
↓
Break Into 100 Small Tasks
↓
100 Workers Process Together
↓
Combine All Results
↓
Final AnswerThat is the complete idea behind MapReduce.
MapReduce in Modern Systems
Even though newer technologies exist today, MapReduce concepts are still extremely important.
Modern cloud systems, analytics engines, and distributed architectures are built using similar ideas.
Understanding MapReduce helps developers learn:
- Distributed systems
- Parallel programming
- Big data engineering
- Cloud computing
Final Conclusion
MapReduce is a simple but powerful concept.
It works in three steps:
Step 1
Break large work into smaller tasks.
Step 2
Process tasks in parallel.
Step 3
Combine all outputs into a final result.
Using Go makes building parallel systems easier because of goroutines and channels.
If you understand this basic idea clearly, you already understand the heart of modern big data systems.
MapReduce is very important in distributed computing because it allows very large data to be processed across multiple computers instead of depending on a single machine. In distributed systems, huge tasks are divided into smaller parts and sent to different servers for parallel processing. The Map phase distributes the work among many machines, while the Reduce phase combines all results into a final output. This makes processing much faster, more scalable, and fault tolerant. Even if one server fails, other machines continue the work without stopping the entire system. Technologies like Apache Hadoop use the MapReduce model to handle massive datasets efficiently in cloud and big data environments.
– Vicky Chhetri